Date : 14 Sep 2025
Incident Response in the Enterprise Security Framework: A Practical Playbook
Why IR matters
Incidents are inevitable; business impact isn’t. A strong IR program reduces downtime, limits blast radius, and preserves evidence for legal/regulatory needs. Align it with NIST 800-61 and/or ISO 27035, but keep the docs human-readable so teams actually use them.
The Incident Response Lifecycle (at a glance)
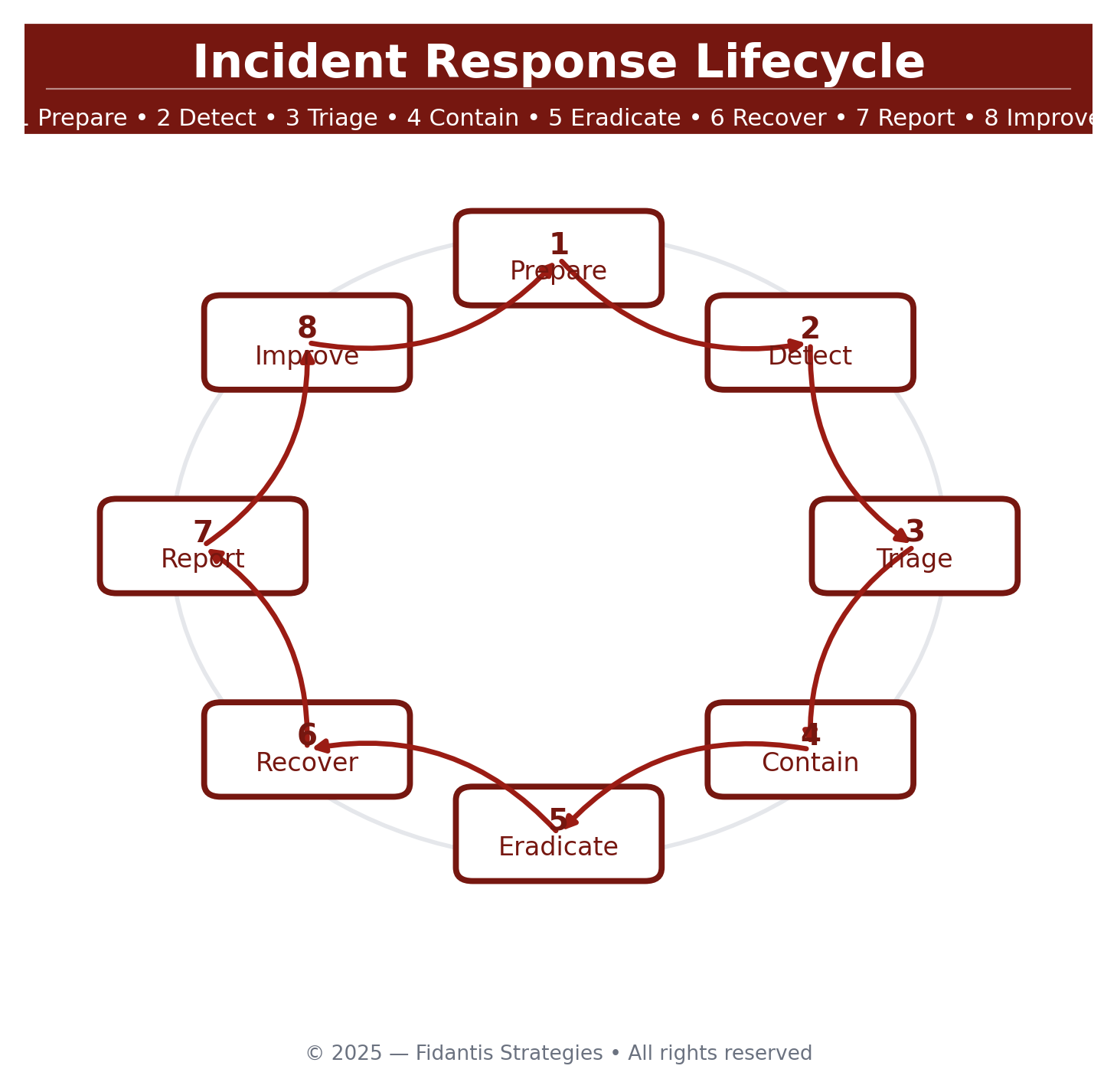 1) Prepare: Plan, People, Playbooks
1) Prepare: Plan, People, Playbooks
-
- Publish an Incident Response Plan (IRP): scope, definitions, severity matrix, communication tree, legal/regulatory triggers.
- Stand up the IRT (Incident Response Team) with clear RACI: SecOps, IT, cloud, data, legal, comms, execs.
- Create playbooks for your top 5 incidents (e.g., ransomware, BEC, lost laptop, cloud key leak, insider exfil).
- Tooling baseline: SIEM, EDR/XDR, SOAR (automation), ticketing, forensics (disk/mem capture), comms war-room (Slack/Teams channel, conferencing).
Outputs: IRP v1.0, on-call rota, playbook library, crisis-comms boilerplates.
2) Detect & Identify
-
- Aggregate telemetry in the SIEM; enforce alert hygiene (noisy rules kill response).
- Use EDR/IDS/IPS and cloud native logs (AWS CloudTrail, Azure/M365, GCP) with guardrails for high-fidelity alerts.
- Define “incident vs. event” criteria to avoid fatigue.
Outputs: Case opened with a unique ID, initial IOC list, working hypothesis.
3) Triage & Classify
-
- Assign severity (SEV) using business impact + spread potential.
- Auto-enrich alerts via SOAR (WHOIS, VirusTotal, EDR process tree, asset owner).
- Decide: continue, escalate, or close as non-incident.
Outputs: SEV rating, owner, first 60-minute action plan.
4) Contain (short- and long-term)
-
- Short-term: isolate hosts, block indicators (IP/domain/hash), revoke tokens, rotate keys.
- Long-term: segmented access, temporary policy changes, break-glass accounts; maintain business continuity.
Outputs: Containment proof (EDR isolation list, firewall changes), blast-radius map.
5) Eradicate & Remediate
-
- Remove malware/persistence, patch vulnerabilities, reset creds, clean up cloud roles and secrets.
- Validate root cause (phish? unpatched service? misconfig?).
Outputs: RCA summary, remediation checklist completed.
6) Recover & Validate
-
- Restore from known-good backups (verify offline/immutable if ransomware).
- Monitor for reinfection; re-enable services gradually (canary users first).
- Confirm integrity (hash checks, config drift, cloud guardrails).
Outputs: Systems back in service, acceptance sign-off from owners.
7) Report & Document
-
- Maintain a forensic timeline: detection → actions → decisions → artifacts.
- Preserve chain of custody (hashes, handlers, timestamps).
- Produce the incident report: scope, impact, costs, notifications (customers/regulators), lessons.
Outputs: Final report, evidence package, notification records.
8) Post-Incident Review (PIR) & Continuous Training
-
- 45–60 min blameless retro: what worked, what broke, what to automate.
- Update IRP/playbooks, adjust controls, and add detections for the missed signals.
- Drill: quarterly tabletops; annual live exercises; red-team where warranted.
Outputs: PIR actions with owners & due dates; playbook/version updates.
Readiness Checklist (copy/paste)
-
- IRP published and versioned; severity & comms matrix included
- 24×7 on-call with escalation to Legal/Comms/Execs
- Top-5 playbooks documented with SOAR steps
- Immutable/offline backups tested (restore proof)
- Evidence handling & chain-of-custody SOP
- Contact roster (internal, vendors, law enforcement, regulators)
- Tabletop schedule (quarterly) and metrics reviewed monthly
Metrics that matter
-
- MTTD / MTTR: mean time to detect / respond
- Containment time: alert → isolation/block
- Dwell time: compromise → detection
- % Incidents with RCA & full report
- Patch SLA compliance (by severity)
- Exercise cadence & findings closed
Automation ideas (high ROI)
-
- Auto-enrich alerts (geo/IP reputation, process lineage).
- One-click host isolation and token revocation.
- Standardized customer/regulator notification templates.
- Ticketing + timeline bot that logs actions with timestamps for the report.
